
百度沈抖谈开源模型,为何前景堪忧?
随着人工智能技术的飞速发展,深度学习模型的应用范围越来越广泛,在这个背景下,开源模型因其开放、共享和协作的优势而备受关注,百度沈抖对开源模型的前景提出了质疑,他认为,开源模型在某些方面存在局限性,难以满足商业应用的要求,我们将从多个角度探讨这个问题,并深入分析沈抖的观点。
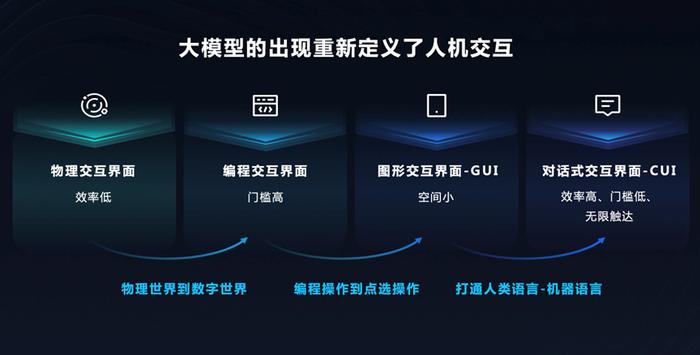
百度沈抖的观点
沈抖认为,尽管开源模型具有诸多优势,但在实际应用中仍存在诸多局限性,开源模型的训练需要大量的数据和计算资源,这对于大多数企业和研究机构来说是一个巨大的挑战,开源模型的定制化程度较低,难以满足企业和机构的特定需求,开源模型的稳定性和安全性也存在一定的问题,沈抖认为开源模型在某些领域难以达到商业应用的要求。
开源模型的局限性分析
数据和计算资源的挑战
开源模型的训练需要大量的数据和计算资源,对于缺乏资源和数据支持的企业和机构来说,训练出高效的开源模型是一个巨大的挑战,数据的隐私和安全问题也是采用开源模型时需要考虑的重要因素。
定制化程度的局限性
尽管开源模型具有通用性,但其定制化程度较低,难以满足企业和机构的特定需求,不同的企业和机构在应用场景、数据特点、业务需求等方面存在差异,因此需要针对不同场景进行定制化开发,而开源模型往往难以满足这种定制化需求,从而限制了其在商业应用中的推广和应用。
稳定性和安全性问题
开源模型的稳定性和安全性也是其应用中的一大问题,由于开源模型的代码是开放的,任何人都可以对其进行修改和贡献,这也意味着其中可能存在潜在的安全漏洞和稳定性问题,在商业应用中,稳定性和安全性是至关重要的因素,因此这也是开源模型在商业应用中的一大挑战。
解析百度沈抖的观点
尽管沈抖对开源模型提出了质疑,但这并不意味着他完全否定开源模型的价值和意义,开源模型在推动人工智能技术的发展、促进技术交流和合作方面发挥了重要作用,我们需要认识到开源模型在商业化应用中的局限性,并需要针对具体场景进行定制化开发和应用。
企业和机构在采用开源模型时,需要充分考虑自身的实际情况和需求,进行合理的选择和应用,对于具有足够资源和数据支持的企业和机构,可以通过改进和优化开源模型,提高其性能和定制化程度,以满足商业应用的需求,对于缺乏资源和数据支持的企业和机构,可以选择与开源社区进行合作,共同推动技术的发展和应用。
百度沈抖的观点提醒我们,在推动人工智能技术的发展过程中,需要充分考虑技术和商业的实际需求,我们也应该认识到开源模型的价值和意义,充分发挥其在推动技术发展、促进技术交流和合作方面的作用,在未来的发展中,我们需要进一步探索如何将开源模型和商业化应用相结合,以满足不同场景的需求,推动人工智能技术的广泛应用和发展。
随着人工智能技术的不断发展和进步,开源模型的应用场景将越来越广泛,我们需要不断优化和改进开源模型,以适应不同领域的需求,企业和机构也需要根据自身的实际情况和需求,进行合理的选择和应用,相信在各方共同努力下,开源模型将会在人工智能领域发挥更加重要的作用,为人类的科技进步做出更大的贡献。
转载请注明来自星韵禾,本文标题:《百度沈抖谈开源模型,为何前景堪忧?》






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号