
碳链强聚集幻觉揭秘,语言模型集体失误的背后原因探究
近年来,随着人工智能技术的飞速发展,语言模型在众多领域展现出了巨大的潜力,一种名为“碳链强聚集”的幻觉却在语言模型领域引发了一系列问题,导致许多大型语言模型性能下降,甚至集体“翻车”,本文旨在深入探究这一现象背后的原因,分析碳链强聚集幻觉的来源及其对语言模型的影响,进而提出针对性的解决方案。
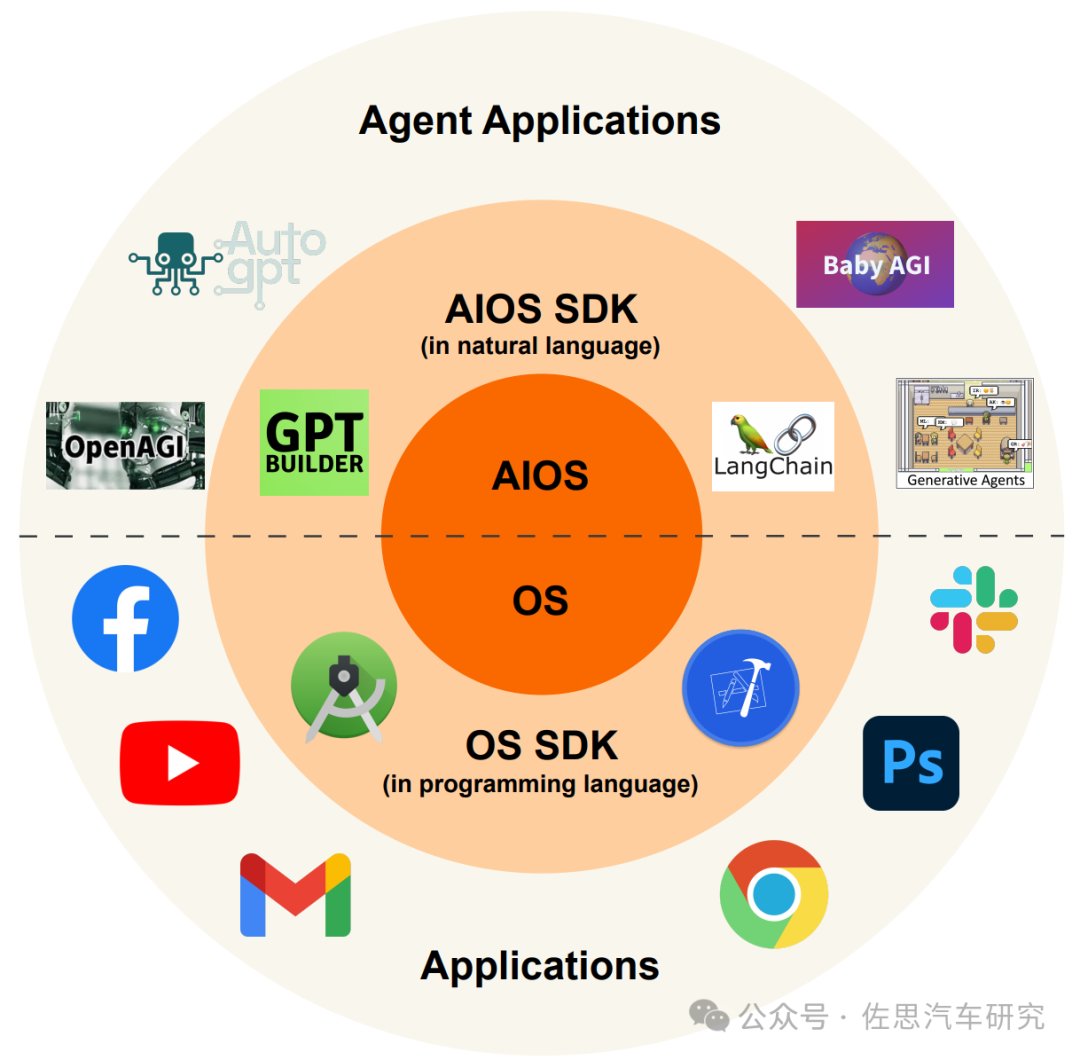
碳链强聚集幻觉的兴起
碳链强聚集幻觉,是一种错误的认知,认为碳链结构在某种条件下具有极强的聚集能力,这一幻觉在语言模型领域尤为突出,由于语言模型的复杂性和数据驱动的特性,一些研究者将这一幻觉引入模型设计,导致了一系列问题的出现。
碳链强聚集幻觉对语言模型的影响
- 模型误导:由于碳链强聚集幻觉的存在,语言模型在设计时可能过度关注碳链结构的聚集能力,忽视了语言的多样性和复杂性,这导致模型在处理自然语言时,无法准确捕捉语言的内在规律,从而产生错误的输出。
- 数据处理困难:碳链强聚集幻觉使得模型在处理数据时容易出现偏差,由于语言数据具有复杂的结构和语义关系,模型在提取特征时可能受到该幻觉的影响,导致特征提取不准确,进而影响模型的性能。
- 模型泛化能力下降:基于碳链强聚集幻觉的模型往往过于依赖特定的数据分布和语境,导致模型的泛化能力下降,在实际应用中,模型可能无法适应不同的场景和数据分布,性能大幅下降。
为什么会产生碳链强聚集这种一眼假的幻觉
- 知识误区:部分研究者对碳链结构的特性存在误解,误以为其具有强聚集能力,这种误解可能源于对某些化学概念的片面理解或者对文献资料的误读。
- 过度简化问题:在追求高效和简洁的过程中,部分研究者可能过度简化了问题,忽略了语言的复杂性和多样性,这使得他们容易陷入碳链强聚集幻觉,忽视其他重要因素。
- 数据驱动的限制:语言模型的设计受到数据驱动的限制,当面临的数据集存在偏差或不完整时,研究者可能倾向于依赖某种假设(如碳链强聚集),从而导致模型的误导。
案例分析
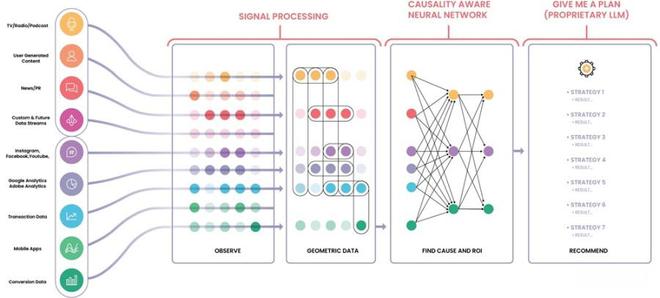
为更好地说明问题,本文选取了几个具体的语言模型案例进行分析,通过案例分析发现,基于碳链强聚集幻觉的模型在处理复杂任务时容易出现错误,且泛化能力较差。
如何避免碳链强聚集幻觉对语言模型的影响
- 加强基础研究:加强对语言模型基础理论和算法的研究,提高模型的准确性和鲁棒性。
- 审慎引入假设:在模型设计中,要审慎引入假设,尤其是未经充分验证的假设,在引入假设时,要进行充分的实验验证,确保假设的合理性。
- 完善数据集:提高数据集的质量和完整性,减少数据偏差对模型的影响。
- 强化模型评估:建立全面的评估体系,对模型的性能进行客观、准确的评估。
- 加强学术交流与合作:加强学术界的交流与合作,共同推动语言模型的健康发展,通过分享研究成果和经验教训,促进学术界的共同进步,共同应对语言模型面临的挑战。
碳链强聚集幻觉是语言模型领域的一个亟待解决的问题,本文通过分析其原因和影响,提出了相应的解决方案,希望本文的研究能为语言模型的进一步发展提供有益的参考和启示。
转载请注明来自星韵禾,本文标题:《碳链强聚集幻觉揭秘,语言模型集体失误的背后原因探究》








 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号